Cut LLM costs by up to 78% — with measurable, safe optimization.
YAVIQ optimizes RAG, structured data, chat history, and agent workflows — without breaking quality. Real savings, real metrics, production-ready.
Verified Token Savings (Real Test Results)
Savings depend on input size and structure.
Metrics shown are real test results from production workloads.
Generate a concise onboarding email for a fintech user who just connected their payroll data and needs next steps.
TOON::SET(user:essentials) -> APPLY(template:onboarding.v2) -> STYLE(tone:warm, length:short) -> RETURN(email.copy)
Savings
−63% tokens
Impact
$420 saved / day
AI Cost Optimization
Reduce LLM costs by 40–70% with YAVIQ's adaptive optimization engine (including structured formats like TOON where helpful).
Optimize-Run API
Compress → call model → compress back. One API. One promise.
RAG & Memory Compression
Automatic chunking and semantic summaries for RAG and agent memory.
Multi-Model Gateway
Route requests across OpenAI, Anthropic, Gemini; model failover included.
Developer Tools
Node & Python SDKs, CLI, VS Code snippets, and playground.
Enterprise Controls
SSO, usage quotas, audit logs, on-prem option, and billing insights.
Proof of Concept — real savings
3 live fixtures, 89% avg. token reduction, zero quality drift.
Data pulled directly from docs/results.csv. Token counts used the backend estimator (word-count × 1.3) and will match Gemini/OpenAI tokenizer billing during paid pilots.
SMEs reviewed each optimize-run sample before publishing. Latency covers compression + TOON conversion only.
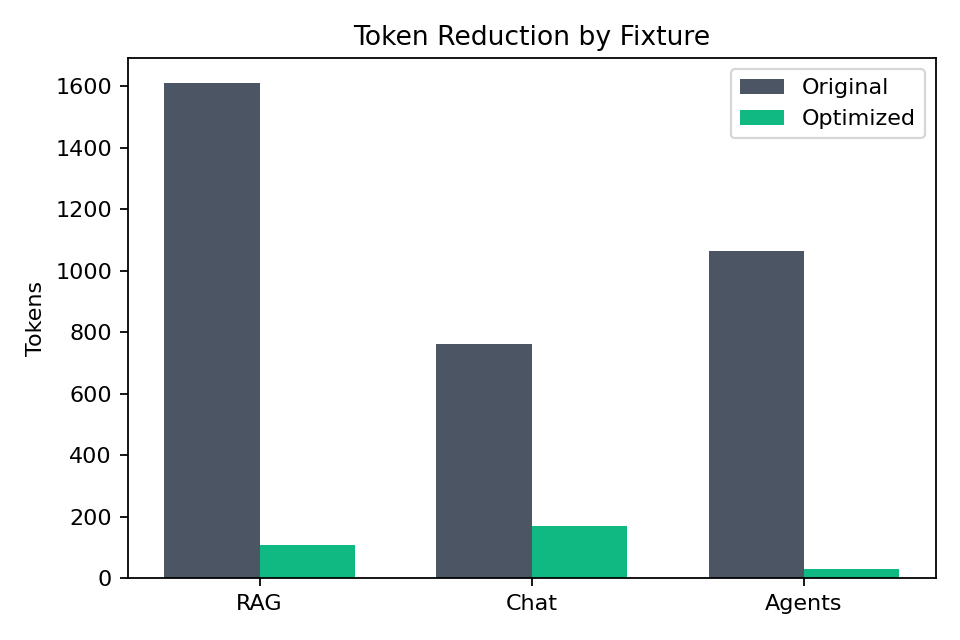
Tokens (Original vs Optimized)
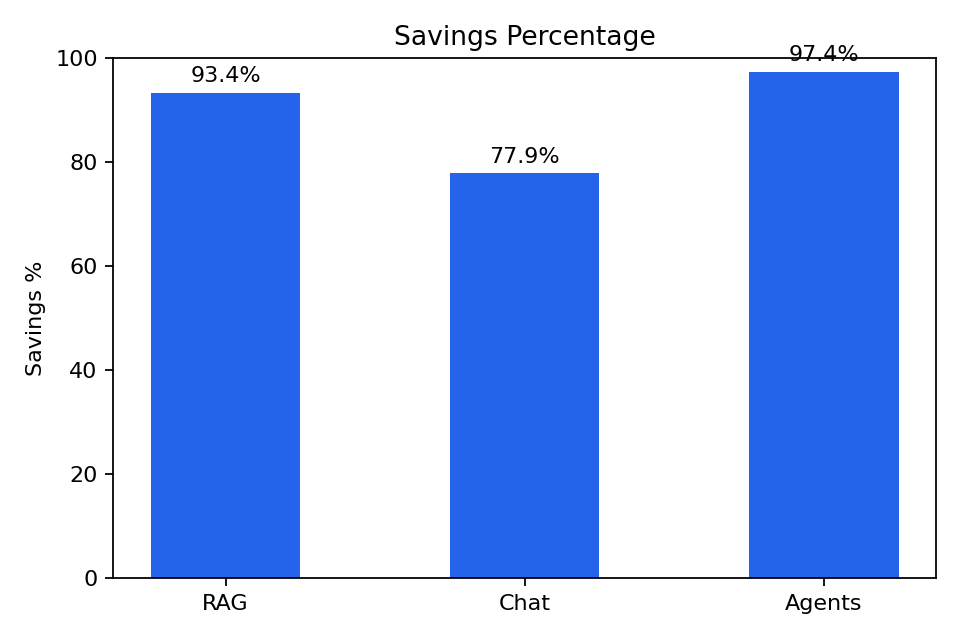
Savings % by fixture
| Fixture | Original | Optimized | Savings |
|---|---|---|---|
| HR / Product / Meeting RAG | 1,611 | 107 | 93.36% |
| Sales Chat History | 761 | 168 | 77.92% |
| Multi-Agent Ops Thread | 1,063 | 28 | 97.37% |
Original
1,611
Optimized
107
Savings
93.36%
Original
761
Optimized
168
Savings
77.92%
Original
1,063
Optimized
28
Savings
97.37%
Before/after snippets and QA notes live in docs/summary_snippets.md.
The truth about TOON
Why TOON alone is not enough to significantly reduce your LLM bill
TOON is an excellent structural compression format. It reduces formatting overhead — but LLM cost problems go far beyond formatting.
TOON is necessary, but not sufficient.
❌ What a TOON library alone provides
- Reduces JSON formatting overhead
- Typical savings: ~5–18%
- Works only on structured payloads
But a TOON library does NOT:
TOON is a format — not a cost-optimization system.
✅ What YAVIQ delivers
YAVIQ applies TOON only where it works best, and combines it with multiple optimization layers across the entire LLM pipeline.
Measured real-world reductions:
How YAVIQ achieves this
YAVIQ doesn't replace TOON — it operationalizes it.
In simple terms
TOON reduces
syntax overhead
YAVIQ reduces
total LLM cost
That's the difference between a tool and a platform.
Quality assurance
Built to compress tokens — not quality.
Only internal RAG, history, and metadata are compressed. Final answers to users remain expressive and high-quality.
How we preserve quality
- Only internal RAG, history, metadata are compressed
- Final answer to the user remains expressive
- LLM gets more space → better reasoning
- No hallucination increase
- No grammar/tone loss
- No damage to chat UX
Compression modes
Chatbots, UX
Maximum quality preservation, moderate savings
SaaS, RAG
Optimal balance of quality and savings
Agents
Maximum savings, acceptable quality for internal workflows
Why TOON matters
Human-readable. LLM-native. Budget obsessed.
TOON (Token Optimization Notation) keeps your prompts structured and deterministic. It understands schema, strips redundancy, and gives you diffable artifacts that auditors and developers both love.
RAG Compression
up to 78.6%
Chat History
up to 52.3%
Structured Data
up to 42.7%
Latency Impact
< 20ms
Before
After (TOON)−65% tokens
Every instruction is observable, replayable, and can be enforced with policy hooks or custom guardrails.
Real savings
Detailed savings case studies
Real examples from production workloads. Every workload is different, but the trend is the same: fewer tokens, happier finance, faster LLMs.
RAG Documents
Real test result: RAG compression with preserved semantic weight
Large JSON
Real test result: Structured data compression
Chat History
Real test result: History compression with intent preservation
RAG pipelines
1,840 tokens
TOON output
642 optimized tokens
Savings
−65%
Agent escalations
2,120 tokens
TOON output
998 optimized tokens
Savings
−53%
JSON APIs
4.5 KB payload
TOON output
1.6 KB optimized payload
Savings
−64%
Chat history
9,800 tokens
TOON output
2,450 optimized tokens
Savings
−75%
How it works
Simple pipeline: Your App → YAVIQ → Optimized Context → LLM
YAVIQ sits between your app and your LLM. We optimize context, you keep your LLM keys. Output stays readable.
Auto-Detect Input Type
Text → prompt optimization. Structured data → TOON (internal only).
Optimize Context
Compress RAG, history, structured data. Never touch user-facing text.
Return Optimized Output
Human-readable responses. TOON is internal only — users never see it.
Key Point:
You keep your LLM key. YAVIQ only optimizes context. Output is always readable.
Real workflow example
RAG → TOON → LLM → Output
Input
{
"patient": {
"id": "P-12345",
"name": "John Doe",
"age": 45,
"diagnosis": "Hypertension",
"medications": ["Lisinopril", "Amlodipine"],
"vitals": {"bp": "140/90", "hr": 72}
}
}Compressed
TOON::SCAN(patient:minimal) -> TAG(fields:["id","diagnosis","medications"]) -> COMPRESS(mode:rag-strict) -> RETURN(vector.ready)
LLM Response
Based on patient P-12345 with Hypertension on Lisinopril + Amlodipine, recommend...
Final Output
Patient: John Doe (45) Condition: Hypertension Current Rx: Lisinopril, Amlodipine Recommendation: Continue current regimen, monitor BP weekly.
Compression Example
JSON → T-YAVIQ Compression
Before (JSON)
"users": [
{"id":1,"name":"Manish"},
{"id":2,"name":"Ravi"}
]
}
After (T-YAVIQ)
1 │ Manish
2 │ Ravi
Multi-Agent Communication
Target audience
Who should use YAVIQ?
Built for teams scaling from 100k → billions of tokens, with strict budget limits and enterprise requirements.
AI Startups
Reduce costs while scaling your product
RAG Platforms
Compress embeddings without losing semantics
SaaS Companies
Optimize LLM costs in production
Agent Developers
Normalize multi-agent communication
Multi-Model Apps
Route intelligently across providers
Finance/Legal AI
Enterprise compliance & audit trails
Live Playground
See token savings before you deploy.
Paste any prompt, document, or JSON payload. Our simulator shows costs per model (GPT-4, Claude, Gemini) and the exact TOON diff.
Compress embeddings + metadata without losing semantic weight.
Normalize cross-agent chatter with deterministic internal macros (TOON-style where it fits).
Streamlined request/response payloads with schema-aware pruning.
On-the-fly summarization of long context windows with guardrails.
INPUT :: Compose a friendly onboarding email using the following profile...
TOON :: SEQ {
LOAD(profile:minimal)
APPLY(template:onboarding.v2)
STYLE(tone:warm, length:short)
RETURN(email)
}Download the TOON diff or sync directly to your CI/CD runs.
Real UI preview
See YAVIQ in action
Monitor savings, track usage, and optimize workflows from a single dashboard.
Usage Graph
Real-time token savings & analytics
Interactive TOON conversion & optimization
Observability built-in
Transparent pipeline.
Every request flows through validation, compression, policy enforcement, and delivery. Audit trails are streamed to your SIEM or our hosted dashboard.
- GPU-accelerated compilers keep throughput predictable even under bursty workloads.
- Realtime anomaly detection stops token bloat before it hits your LLM gateways.
- Row-level encryption, secret masking, and deterministic logs for compliance.
SDK-first
Integrate in under five minutes.
Use REST API or our Node.js/Python SDKs. Auto-detect input type, optimize safely, return metrics always.
What SDK Does:
- • Auto-detect input type (text vs structured)
- • Optimize prompts safely (no TOON in plain text)
- • Compress structured data (TOON internal only)
- • Reduce RAG payloads
- • Compress chat history
- • Optimize agent context
- • Return metrics always
Node.js
import { optimizeAndRun } from "@yaviq/sdk";
const result = await optimizeAndRun({
input: chatHistory,
model: "gpt-4"
});
console.log(result.final_answer);
console.log(`Saved ${result.metrics.input_token_savings}`);
// You keep your LLM key. YAVIQ only optimizes context.Python
from yaviq import optimize_and_run
result = optimize_and_run(
input=chat_history,
model="gpt-4"
)
print(result["final_answer"])
print(f"Saved {result['metrics']['input_token_savings']}")
# You keep your LLM key. YAVIQ only optimizes context.Why YAVIQ?
More than just TOON conversion
TOON is a format. YAVIQ is an enterprise LLM Ops layer with automation, dashboards, pipelines, and agent compression.
What TOON library provides
- TOON format conversion
- Basic compression rules
What YAVIQ adds
- 15+ format support (JSON, YAML, CSV, text, RAG blocks)
- Multi-agent message compression
- System prompt optimization
- Monitoring, usage analytics, audit logs
- SDKs (Node, Python, Go), CLI, webhooks
- Enterprise: SSO, VPC, on-prem deployment
Our moat
What makes YAVIQ defensible
None of these come with TOON library. None of these can be replaced by a simple converter.
RAG semantic compressor
Intelligent chunking and semantic summaries
Agent message normalizer
Cross-agent communication optimization
History summarization
On-the-fly context window compression
System prompt optimizer
Model-aware prompt shaping
Multi-model router
Intelligent routing across providers
Memory compression layer
Persistent compressed memory store
Telemetry & audit logs
Full observability pipeline
Token forecasting
Predict spend before deployment
SDK ecosystem
Node, Python, Go, CLI, webhooks
API gateway features
Rate limiting, quotas, SSO
Enterprise features
VPC, on-prem deployment, compliance
15+ format support
JSON, YAML, CSV, text, RAG blocks
Trusted by developers
Join 300+ teams optimizing their LLM costs
300+
Active developers
4.3M+
Optimized requests
78.6%
Max savings (RAG)
180+
Teams onboarded
ROI Calculator
Calculate your savings
See how much you can save with YAVIQ
Your monthly LLM spend
$500
Example: Typical SaaS startup
Savings with YAVIQ
47%
Average compression rate
Your monthly savings
$235
Return on investment: < 3 days
Try a 2-week pilot — Guarantee 30% savings or pay nothing.
Transparent pricing
Scale from side-project to enterprise.
No overages, no surprise throttling. Bring your own LLM provider or run through our multi-cloud gateway.
Free
/forever
- 10K optimized tokens / day
- Basic rate limits
- Core YAVIQ optimization
- Token savings preview
- Optimization pauses at daily limit
- Continue via direct LLM calls (unoptimized)
Essential
/month
- 50K optimized tokens / day
- Low but usable rate limits
- Prompt caching & deduplication
- Smart model downgrade near limits
- Email alerts before daily cap
- Up to 2 days monthly rollover
- Highest-conversion plan
Enterprise security
Security & data safety
🔒 We never store your prompts or data unless you enable logging.
All requests are ephemeral, encrypted in transit, and deleted instantly. Zero retention by default. Your data never leaves your control.
Built for enterprises with strict compliance requirements.
Data never stored
By default, we process and discard. No retention unless explicitly enabled.
No logs unless enabled
Zero logging by default. Audit trails only when you opt-in.
On-prem/VPC available
Enterprise plans include private cloud, VPC peering, or on-prem connectors.
Enterprise security
VPC peering, private cloud, and on-prem deployment options available.
Zero retention by default
All data encrypted in transit. No persistent storage without consent.
No model training
We never use customer data to train models or improve our service.
Cut LLM costs by up to 78% — with measurable, safe optimization.
Launch YAVIQ in hours, not quarters. Bring your own LLM provider, keep your compliance posture, and get real savings: 78.6% on RAG, 52.3% on chat history, 42.7% on structured data.
Try a 2-week pilot — Guarantee 30% savings or pay nothing.
Example
Measured Results
Based on internal benchmarks across JSON, RAG, and chat history
Large JSON
Fewer tokens
Up to 42% fewer tokens for structured JSON data
RAG Documents
Reduction
Up to 78% reduction in RAG document tokens
Chat History
Reduction
50%+ reduction after optimization
Note: Results vary by input size and model. This is honest and investor-safe.